


L2 Planet Focus: Polygon Hermez
In this Issue of the L2 Planet Focus series, we focused on Polygon Hermez.


Polygon-Hermez is a scalability solution that uses zkRollup technology.
“Hermez 1.0”, launched in March 2021, was a zkRollup that only allowed token transfers, which means smart contract execution was not possible.
Hermez 2.0, on the other hand, is designed as a zkEVM-zkRollup, that is, a smart contract application.
While developing the EVM, it was not designed for use with zero knowledge, as some elements used in Ethereum (Keccak, etc.) create a huge load in the zk-proof phase. In other words, it is a difficult process to develop a design in which zero knowledge and EVM work together.

The Hermez team is working on a zkEVM, but it should be noted that not every project referred to as a zkEVM is the same.
zkEVMs are divided into 3 different levels:
Language Level
Bytecode Level
L1-EVM Level
The first level is the "language level".
Here, a programming language used for EVM like Solidity is converted into a zk-friendly programming language like Cairo (Solidity>Cairo transformation given in the example is done with WARP that was developed by Nethermind). After that this Cairo code works in its own VM. In this way, zk developers can freely develop a zk-compatible VM without being bound by the limits of the EVM. However, this also means that smart contract developers need to learn a new programming language for a smooth developer experience. The project targeting this is StarkWare-StarkNet.
The second level is the "bytecode level".
The goal here is not to convert Solidity to a zk-friendly language and execute it in a custom VM, but to create zkRollup that works directly with EVM compatibility. While being deployed to the EVM, smart contracts written with Solidity are converted into "bytecodes" that the EVM can understand. While the EVM can understand and execute these bytecodes, operating systems can understand and execute OPCODEs that are made up of bytecodes. Here, "bytecode-level" zkEVMs work in harmony with these OPCODEs of the EVM. The two projects targeting this are Scroll and Polygon-Hermez.
The third level is the “L1-EVM level”, or “consensus level”.
Here zkEVM is directly aligned with the L1 consensus. In this way when a block is created evidence that the block is correct is also created. Thanks to cryptographic breakthroughs such as PLONK, and HALO2 (SNARKs), the entire blockchain can be verified, so that nodes wanting to join the system only need to verify that this proof is correct when they want to sync with the blockchain. This is one of Ethereum's long-term goals.
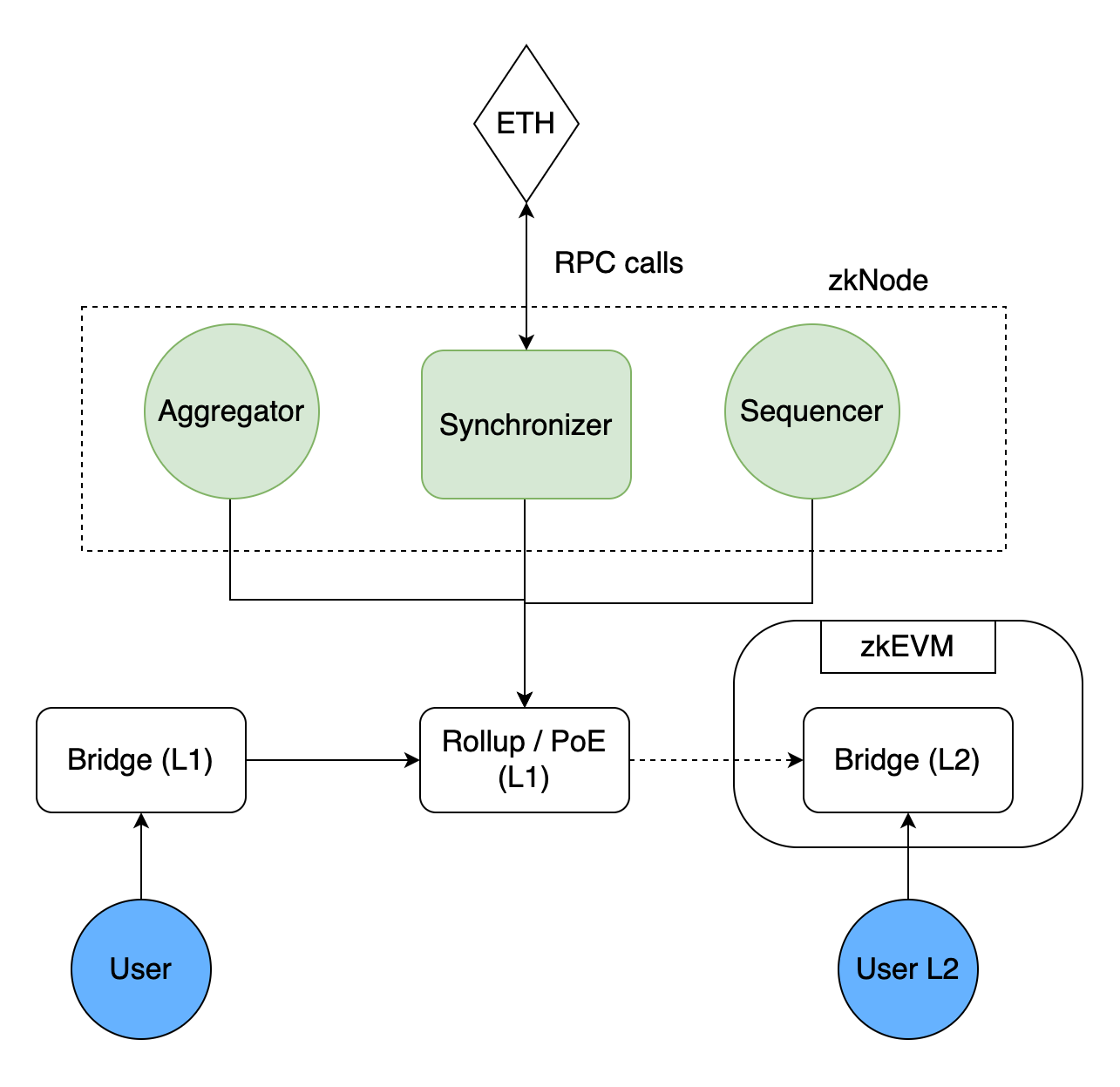
The important elements of the Hermez 2.0 architecture, developed as a bytecode-level zkEVM, are:
Proof Of Efficiency
zkNode
zkProver
LX-to-LY Bridge
Proof of Efficiency
Proof of Efficiency is a mechanism developed by the Hermez team to decentralize their zkRollup and enable permissionless participation in the system. The most important elements concerning decentralization in zkRollup operators are:
Creating batches must be permissionless.
The system must be protected against malicious attacks.
The system must avoid the control of a single authority.
In the Proof of Efficiency (PoE) model, the batch creation process consists of two different steps involving two different actors. While the Sequencer takes charge in the first step, the Aggregator takes charge in the second step.
Sequencer

Sequencers collect the transactions made in L2, turn them into a “batch” and then send this batch to the L1 (PoE smart contract) with the data of the transactions in it. Being a Sequencer is incentivized by transaction fees for batched transactions, and anyone can become a Sequencer.
Sequencers pay two different transaction fees when they create a "batch" and send it to the network:
1-L1 transaction fee for data sent to L1
2-$MATIC deposit fee determined by the L2 protocol
Of course, batches sent to L1 (PoE smart contract) are only considered valid after being proven with a validity-proof. At this stage, Aggregators, the second actor in the system, come into play.
Aggregator

The task of the aggregators is to generate the proof of the batches sent to L1 (PoE smart contract) by the sequencers. Aggregators are actually in competition with each other because the first batch whose proof is created is accepted by the smart contract and receives some transaction fee from within the batch for which it creates the proof.
Thanks to this whole system, batch and proof creation processes in rollups are not dependent on a single actor but are designed in a way that anyone can participate.
The final schema is this:

ZkNode

zkNode is the software used by Hermez 2.0 nodes. Those who want to be a Sequencer or Aggregator join the system by establishing a node.
Apart from being Sequencers and Aggregators, Nodes can also act as "Synchronizers". Synchronizers ensure that the batches sent to Ethereum L1 and the proofs of those batches are synchronized.
zkProver

Aggregators do something that Sequencers do not: create Validity-proofs. They use the zkProver system to create these validity-proofs.
zkProver:
Main State Machine Executor
Secondary State Machines
STARK-proof builder
SNARK-proof builder
The Main State Machine Executor is responsible for executing the zkEVM. EVM bytecodes are executed with zkASM (zero-knowledge assembly language) developed by the Hermez team. In addition, the "polynomial constraints" of the batches (processes) that will be proven to be correct with STARKs and SNARKs in the future are also determined here. For this, PIL (Polynomial Identity Language) developed by the Hermez team is used.
Secondary State Machines refers to the sum of “Binary SM, Memory SM, Storage SM, Poseidon SM, Keccak SM, Arithmetic SM” in zkProver. These are essentially the computations required to prove the correctness of transactions in the zkEVM.
With the STARK Proof builder, a STARK proof is created that meets the "polynomial constraints" created in the State Machine for batch (operations).
With SNARK Proof Builder, proof of the accuracy of STARK evidence created in the STARK Proof Builder is created. Because the STARK evidence is larger than the SNARK evidence, it is more costly to verify the STARK evidence in L1, so it is a SNARK not validity-proof STARK sent to L1.
LX-LY Bridge
The bridge connecting L2 and L1 is actually a smart contract and is generally only responsible for making transfers between L1 and L2. But the bridge in Hermez 2.0 acts not only as "L1-L2 transfer" but also as "L2-L2 transfer".
The bridge has two smart contracts, one in L1 and the other in L2.

All L2 bridge smart contacts have a merkle tree called “exitTree”. When a transfer is requested from the rollup, this operation is added to the exitTree as a "leaf" one by one. So, for example, when you want to transfer from "X ERC20 to Y L2B" while in L2A, this process is added to L2A exitTree.
The bridge smart contract in L1 has a merkle tree called globalExitTree. This merkle tree represents all exitTrees made on L2s. Thus, with a globalExitTree root, you can have all exits in L1 and L2.
Let's explain the operation of the bridge through an example:
Suppose there are two different L2s in the mainnet and assets are to be transferred on the route L1>L2A>L2B>L1.
When $MATIC tokens in L1 are to be transferred to L2A, this transaction is sent to the L2A bridge contract, and this bridge contract adds the transaction to its exitTree as a leaf. Each time L2A is batched, this exitTree is sent to the L1 bridge contract and added to the globalExitTree there. In L1, $MATIC tokens are locked, the rollup prints tokens representing $MATIC with its own wrapper mechanism.
This wrapped $MATIC then adds the bridge contract in L2B to its exitTree as a leaf when it is desired to be transferred from L2A to L2B. In addition, $MATIC tokens subject to these transactions in L2A are marked as "nullifiers", so the same tokens cannot be transferred twice. When L2B is batched again, this exitTree is added to the globalExitTree in L1.
When it is desired to return to L1 again, the L2B bridge contract adds this transaction to its exitTree. When L2B is batched, this process is also added to the globalExitTree in the L1 bridge contract and the tokens are transferred to L1. Of course, the wrapped tokens in L2B are burned.
Conclusion
The scheme consisting of the sum of all these elements:
That’s all from L2 Planet, for now, hope to see you in the next Polygon issues :)